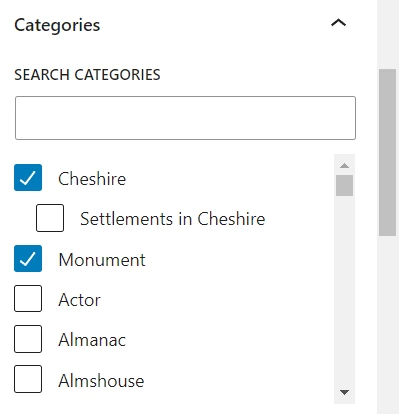
WordPress uses the term category slightly differently to the way that we employ it here on Engole. We don’t have a category of Monuments in Cheshire for instance, but we can categorise an individual structure as a monument and in Cheshire, making it easier for readers searching for such monuments to find.
The first thing to understand is that even if an article is uncategorised, it will still appear in search results if its title or content contains any of the words searched for. The Relevanssi plugin that we use for user searches – not admin searches – assigns levels of relevance in descending order to three things: the article’s title, its categories, and its content.
To take one example, our article on the fund manager George Ross GoobeyInnovative pension fund manager (1911–1999). is uncategorised, but if you do a search for “goobey” – capitalisation is ignored – you’ll see this:

We don’t have a category for “fund manager”, but because that phrase appears in the text of Goobey’s article this is what you’d get if you searched for that:

George Ross Goobey still appears first because his article contains the phrase “fund manager”, and the others are included because their articles contain the words “fund” and “manager”.
Categories
Our use of categories is simply to refine searches for the benefit of readers, as this comparison with a Wikipedia search hopefully demonstrates. Suppose a reader is searching for “churches in somerset”. This is what they’d see on Wikipedia:
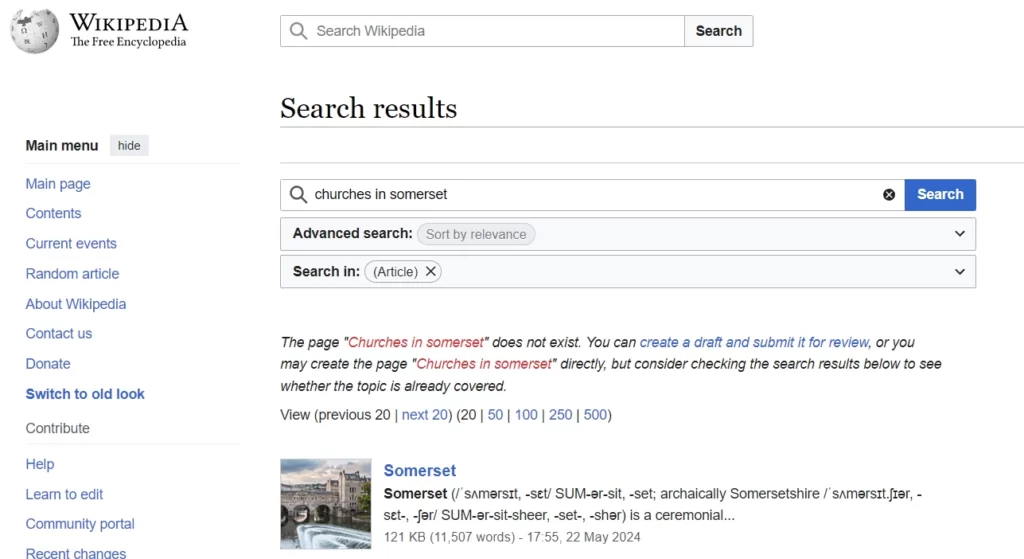
In other words, someone would need to have written an article titled “Churches in Somerset”. Compare that with our approach, which is to categorise a church article as “church” and “somerset”, without the need for a “Churches in Somerset” article. This is what we’d return for that same search:

So, in essence, categories are convenient search terms. What we’re doing in assigning categories is to second-guess what terms users are most likely to include in their searches, singly or in combination, and what they’d expect to see.
Noise words and synonyms
Noise words are commonly occurring words such as “a”, “in”, “the”, “please” … which are ignored during the search. So there’s no difference between searching for “churches in somerset” and “somerset churches”.
We also have a database of synonyms, so every category is singular, eg. “church” not “churches”, as churches is defined as a synonym of church; similarly with “motorbike(s)” vs “motorcycle(s)”. All searches are examined for synonyms and modified accordingly before being passed to the search engine.
For instance, a search for “british motorbikes” would be translated to “british motorcycle”:

Just like categories, these synonyms are solely for the benefit of readers. We maintain a log of all searches so that we can monitor things like misspellings such as “phenakistiscope”, and correct them to phenakistoscopeOptical toy producing the illusion of moving images, popular during the Victorian era., a pretty common error among those interested in Victorian toys.
To put the significance of that in context, Wikipedia has more than 2.3 million “List of X’s in Y” articles, such as “List of British Cars”, more than 37% of all its articles. But because we have defined “list” and “of” be noise words, and “cars” to be a synonym of “automobile”, without us having an article called “List of British cars” we would return this:
